Interrupts vs. Polling
Pretty obvious stuff.
- Polling wastes resources.
- Polling is simple, requires no special hardware or CPU design.
- Interrupts are synchronous; CPU can go off and do something else.
- Interrupts are more complicated, more difficult to implement.
Ada Interrupts vs. Java Interrupts
In Ada interrupt handling is a hybrid between a ‘procedure’ model & ‘shared-variable condition synchronization’ model. Interrupt is mapped to a protected procedure call and registers are accessed via program variables.
In Java interrupts are firings of asynchronous events where the handler is a schedulable object (whatever one of those are).
Both Ada and Java do not support parameter passing.
- In a procedure model an interrupt is viewed as a procedure call.
- In a shared-variable condition synchronization model an interrupt is like a signal/send operation on a shared variable.
Interrupts Ada
- While an interrupt is being handled, more of the same are blocked.
- Use pragmas:
Interrupt_HandlerandAttach_Handlerfor dynamic/static interrupt handler attachment respectively. - Procedures capable of dealing with interrupts must be specified at compile time.
- Ada does not allow select statements in interrupt handlers. This is because it is a protected action.
Task Model
- Priority Inversion: this is where due to runtime circumstances a higher priority task is waiting for a lower one.
- Priority Inheritance: task priorities are not static; priority of a task is max of its own priority and others time-dependent on it.
- Immediate Priority Ceiling Inheritance: Each task has a default priority. Each resource has a priority that is the maximum of all task priorities for tasks that use it. Dynamic task priority is then
max(default, max_resources)). - Deadline Monotonic Priority Assignment: closer deadline = higher priority. This is optimal O believe, and is the standard you should use when assigning task priorities.
Priority Ceiling Protocol vs. Simple Priority Inheritance
Simple priority inheritance does not take into account resources that tasks use. Priority Ceiling protocol does (see above).
Priority ceiling protocol means tasks aren’t blocked at the resource level, because either all or none of their resources are available due to the nature of the priority assignment. If you are asked a question on this you might be asked to give an entire example of execution (e.g. which task executes when) for both PCP and simple priority inheritance.
Calculating vs. Analysing Worst-Case Execution Time
Measuring
- Difficult to be sure if worst-cases have been observed.
- Doesn’t require anything extra.
Analysis
- Need an effective model of the processor.
- Can be exact; can artificially create worst-case for analysis.
Combination
A combination of the two is possible:
- Use measurement for code blocks.
- Use analysis for complete components.
Response Time Analysis versus Utilization-based Analysis (for FPS)
Utilization based analysis is not exact, and not extendable. It is:

Where N = number of tasks, C = WCET, and T = Period. There is a particular ‘magic number’ which, if not exceeded, means the test has been passed.
RTA is exact and extensible, and covered in lots of detail below:
Response Time Analysis (and inheritance)
With simple priority inheritance, blocking time for task i is:

where usage is a 0/1 function and k ∈ all critical sections in the system.
The usage function works as follows:
usage(k,i):
if exists a task with priority < task i and uses k
AND exists a task with priority >= task i and uses k:
return 1
else:
return 0Note that this function includes the task in question as far as I can tell (hence the >=). So the task with highest priority can be blocked too!
With this in mind, Response time is now defined as:

Explanation for this is now given below:
Response Time Analysis
Following on from the above equation (just don’t include B if you don’t want to take in to account blocking time), I = interference from other tasks and is given by:
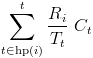
Where (you should know this already) R_i is the response time for task i, T_t is the period for task t, and C_t is the worst case execution time for task t. The set hp(i) is the set of tasks with a higher priority than task i. This equation may look a bit odd but if you think about it long enough it’ll make sense.
This results in R_i being a recursive equation, so you have to iteratively calculate it, starting with I = 0. Eventually (due to the ceiling function) it will stabilise. It can also stabilise at several different values, so you may have to artificially use different values for R_i and insert them in to the equation.
As a tip when revising, use Wolfram Alpha to compute the answers for you, as it will also plot a graph which will help you understand how it stabilises multiple times.
RTA shows a task missing a deadline when the largest possible response time according to the RTA is greater than the task deadline.
FPS versus EDF
FPS is fixed priority scheduling; this is what you mostly deal with in RTS. But there’s also Earliest Deadline First scheduling, which is a dynamic scheduling system. In EDF, priorities are based on the absolute nearest deadline.
- EDF can schedule anything FPS can, and can also schedule a few other task sets too.
- However EDF requires more overhead, because it is dynamic.
Utilisation-based tests for EDF are simpler, and necessary & sufficient; they are only ‘sufficient’ for FPS.
- Necessary: Failing a necessary test = unschedulable.
- Sufficient: Failing a sufficient test != unschedulable.
Implementing EDF:
From a task’s point of view.
- Work out your next deadline.
- Check if anything has a closer deadline; lower your priority if it does, otherwise set yourself the runnable priority.
- Do work.
- Work out what needs to run next, using a very high deadline to avoid having yourself run again.
Monitors in Java
Firstly a recap: Monitors encapsulate data, and provide mutual exclusion and condition variables for that data.
Java provides shared data encapsulation through its object-orientation, and provides mutual exclusion through synchronized methods (methods with the synchronized tag). Java also provides nested calls; which apparently is important for monitors but I have no idea why, but it’ll give you a mark to say that.
Java also additionally gives the ability to have both synchronized and unsynchronized methods in a ‘monitor’ (useful for say…many readers, 1 writer). You can also access the lock remotely (e.g. not from within a method). However Java doesn’t really have condition variables, so threads must continually retest their wait conditions themselves.
Ada Entries
Tasks use entries to communicate with other tasks. Tasks indicate they are willing to receive using accept statements. Condition syncing is support using guard clauses.
Protected Types use entries to provide condition synchronization and mutual exclusion; an entry can have guard clauses and is only allowed to be ‘entered’ by one task at a time.
The fundamental different is that tasks use entries for control oriented synchronization, whereas protected types use entries for data oriented synchronization.
What about entry families?
Entry families allow for the definition of an array of entries for example:
type Channel_Number is new Integer range 1..7;
task Multiplexor is
entry Channels(Channel)(Data : Input_Data);
end Multiplexor;You would then call the entry like so:
Multiplexor.Channels(3)(D)Where D is some input data.
Entry families can be defined in both protected entries and task entries. From the callers point of view they are identical. However accept statements in tasks must explicitly state which member of the entry family they are accepting for, whereas protected type entries can use something like (for X in Channel_Number) to get all of it.
Ada and Java Exception Handling
- In Ada the domain of the exception is the block (e.g. the begin). In Java it is explicitly defined by a
trystatement. - Both have exception propagation.
- In Ada types of exceptions must be specified at package level.
- Java uses
catchand can catch generic exceptions with heirarchy. But Ada has no heirarchy. - In Ada you can only pass strings to exception handlers.
- Java supports finally statements; stuff to run whether an exception has been handled or not. Ada doesn’t really have this.
- In Java exceptions are part of the OO Model. In Ada exceptions are predefined types.
- In Ada subprograms can propagate/identify any exception types. In Java subprograms must explicitly declare what checked exceptions it can throw.
In Ada if an exception is raised inside an entry it will be re-raised in both the called and calling task. Therefore the calling task will need to protect itself against the exception. You can stop that from being necessary by handling the exception within the accept statement so that it isn’t re-raised in the calling task. Alternatively add exception handling in all possible clients.
If you’re asked a question about this, you need to be aware of the actual exceptions that might be raised & when. Detail it all!